How to use delta lake in Apache Spark?
Welcome back. In the previous video of this series, I talked about some common problems that
we face with Apache Spark implementation and learned
why do you need
delta lake for apache spark.
In this article, I will talk about Delta Lake and try to understand the following.
- What is Delta Lake and what it brings to the table?
- How can you leverage it in your project?
Apache Spark is just a processing engine. It does not come with its own storage, cluster manager, or metadata store. For all these requirements, it relies on some other systems. Right? You have multiple options for storage such as HDFS, Amazon S3, and Azure Blob Storage. You can run Spark on YARN, Apache Mesos and Kubernetes. Spark allows you to create database objects such as tables and views. These things require a meta-store, and Spark relies on Hive meta-store for this purpose. And theseare the main reasons why Spark never provided some of the most essential features of a reliable data processing system such as Atomic APIs and ACID transactions.
What is Delta Lake?
If you want to provide ACID properties, you need to place an intermediary service between Apache Spark and the storage layer. And that is what the delta lake is doing.

Delta Lake plays an intermediary service between Apache Spark and the storage system. Instead of directly interacting with the storage layer, your programs talk to the delta lake for reading and writing your data. Now the responsibility of complying to ACID is taken care of by the delta lake. The underlying storage system could be anything like HDFS, Amazon S3, or Azure Blob Storage. All you need to make sure that you have the correct version of delta lake that supports your underlying storage system. That's all at a very high level. There are minute details to answer the How question. But at the high-level, this is what the delta lake is. An intermediary between Apache Spark and your Storage layer.
Starting Spark with Delta Lake
Great! Now let's try to understand how it helps us in fixing those problems that we discussed in the earlier session on delta lake. We want to try things and see them in action. So, let's start Spark Shell with delta lake enabled.
So, the delta lake comes as an additional package. All you need to do is to include this dependency in your project and start using it. Simple. Isn't it? I am adding this package to spark-shell, and I will be able to use it on my local machine for my local file system. However, you can get it working in the same way on HDFS as well.
Using Delta Lake in Apache Spark
Great! So, your Spark shell is up. Let's try to understand the delta lake ACID feature.
In the earlier session, we used following code to demonstrate that the Spark overwrite
is not Atomic and it can cause data corruption or data loss. Right?
The first part of the code imitates job 1 which creates 100 records and saves it into the
test-1 directory.
The second part of the code imitates job 2, which tries to overwrite the existing data
but raises an exception in the middle of the operation.
The outcome of these two jobs was a data loss. In the end, we lost the data that was
created by the first job. Right?
Now let's change this code to work with delta lake package.The delta lake saves data in
parquet format. So, we change the csv method to save and define format as delta. That is
all. The first job is now migrated to delta lake. Same changes to the second job. That's it.
Schema Validation in Delta Lake for Spark
If we execute this code, will it work? It should. But there is a small problem here. Both of
these jobs are creating a data frame and trying to save it. Right? But both of these do not
have the same schema.
You can use the following code to print the schema for both of these jobs.
Using Delta Lake for ACID in Spark
Great! But we wanted to run these jobs and test if the overwrite is causing the same problem as we saw in the previous session. I have modified the code to force the column name and the new code looks like following.
Execute the first job and count the number of rows. As expected,you will get 100 rows. If
you
check the data directory, you will see a snappy compressed parquet file. That one is the
data file that holds 100 rows which you saved. You will also see a delta log directory that
contains a JSON file. You can open the file and check the content. The file contains Commit
Info. So, that one is a commit-file. And it also contains a bunch of other information. We
will come back to this file once again.
Now execute the second job.
What is your expectation form the second job? As earlier, this job should try to do the
following things.
- Delete the previous file.
- Create a new file and start writing records.
- Throw a runtime exception in the middle of the job.
As a result of exception, the job level commit does not happen, so the new file is not
saved. But since we deleted the old file, we lost the existing data. That's what was
happening as I showed in the earlier session. Right?
But now if you execute the second job, you will still get an exception.Then, count the
rows. What do you expect? Zero rows. Right?
But what do you get? 100 records. Voila! You didn't lose older records. Looks like delta
lake did the magic. Overwrite became atomic. Isn't it?
Let's look at the data directory, you will find two parquet files.
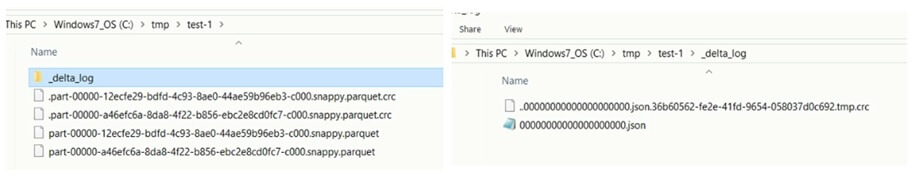
One file was created by the first job and the other file is created by the job 2. So, what
exactly happened there.
Instead of deleting the older file, the job2 directly created a new file and started
writing data into the new one. This approach leaves the old data state unchanged. And that
is why we didn't lose the older data because the older files remain untouched.
Wait a minute! The new incomplete file is also there. Right? Then how come we get row
count as 100. Why the data in the new incomplete file is not counted?
Valid question. Right?
The secret is hidden in the log directory and managed using the commit-file. If you look
at the log directory, you will still see only one commit file. The second job could not
create a commit-file because it failed in the middle. Right? Now, when we read a delta
table. The Spark read API will not read files for which there is no commit log. Simple!
Isn't it?
Great! What if the overwrite successfully completed. Let's check.
This time, we don't want it to raise an exception and overwrite the old 100 records with
just 50 records.
Now the record count shows 50. As expected. So, you have overwritten the older data set of 100 rows with a new data set of 50 rows. Right? What do you expect in the data directory? One more parquet file. Right? And a new commit log.

Great! Now we have three data files and two commit logs. When we read this delta table using
Spark API, how does Spark know, which file to read, and which ones to ignore? Let me
explain.
The Spark data frame reader API will first read the commit log. It opens the first
commit log. The first commit log says, add the first data file in the read list. Then it
will read the second commit log. The second commit log says, add the second file and remove
the first file. So, you will be left with one snappy compressed parquet file. And hence, the
data frame reader would read only one most recent file and ignore the other two files.
Amazing! Isn't it?
So, what we concluded? Delta lake brings a commit log to Apache Spark and makes Spark
data writer APIs atomic solving the data consistency problem. Once that consistency problem
is solved, delta lake would be able to offer updates and deletes.
How to delete and update records in Apache Spark
Let's see how deletes and updates are implemented. The following line of code will read the batch 1 of data from a CSV file. Then we perform some simple transformation. Finally, we save the transformed dataset as a delta table.
Now, once we have a delta table. You might have requirements to read it, maybe delete some
records or update something in this table.
Reading is simple. You can read it as a data frame. Use the following code. And the
below code gives you a data frame. Once you have a data frame, you can apply all kind of
things that you can do with the data frame.
There is another way of reading a delta. Here is the code.
The above code gives you a delta table. Once you have a delta table, you can do some
additional things such as delete and update. And to your surprise, your original delta table
value is automatically refreshed. You don't need to read it once again after deleting or
updating some records.
If you look at the backend – data directory, you will find a new data file and a new
commit log. Let's see what exactly happened when we delete something from a delta table.
Now you understand what exactly happens when you delete or update. Delta lake API will
read the older file, modify the content, I mean to delete or update, whatever you applied,
and write a new file with the modified data.
Now think about the other jobs reading this same delta table. If they started reading
beforewe committed our update, they would see commit-log zero. Right? Because commit log one
is not yet created. So, they will read the first data file only.
If a reader process starts after we committed our delete. They will see both the commit
log entries. The first commit log wants to add the first data file. But the second commit
log instructs to remove the first data file and add the second data file. As a net result of
these two commit logs, your reader process will read only the second data file. This is how
reads will only see the committed transactions.
Merge statement in Apache Spark
Let's reset our directories and start fresh. We are going to mock a scenario where you
already have a delta table and you have performed some initial load in this table. So, you
have some records in the table.
Now you are ingesting some data from a source, performing some transformations, and
finally, merging the new inputs with the existing delta table. Merging operation, as we
know, is a type of upsert operation. So, if you got an existing record again in the new
batch, update the old record with the new values. And if it is a new record that does not
exist, insert it. Right? Let’s do it.
First, this is to read the initial load. And here is the code. As a best practice, we do not
infer a schema, but we specify one.Then, we transform the raw data as per our need.Finally,
write it as a delta table. This step will create the delta table and load the data.
Now, we got our new batch of data. Let me load it in a data frame, apply the same
transformation. Finally, we merge it.
So, we start with the delta table. Give it an alias as stars. And call the merge method. The
merge method takes two arguments.The first argument is the data frame of new inputs. We also
give it an alias as inputs. The second argument is the matching condition string. In our
case, it is as simple as stars.FName == to the inputs.FName. That's all.
The merge method will return a delta merge builder. The delta merge builder comes with
three methods: when matched, when not matched, and the execute method. Rest is
straightforward. When matched, use the update expression. When not matched, insert all
columns. And finally, execute the whole thing.
Time travel in Spark Delta Lake
Finally, let's talk about time travel.Delta table allows you to get the version history of your table.

Let me show you. The most interesting this is the history method returns a data frame. So,
you can query it, do min, max and join it with some other data set.
In our example,we have two versions. Version 0 and version 1. And you can also see the
timestamp which is the commit time. Once you know the versions, you can read any of these
available versions.
Here is the code. Read the delta table into a data frame with the version as of zero.
You can also read it using the commit time.
There are few specifics of reading with commit time. Let me explain.
You can't read anything before the first commit time and after the last commit time.
What does it mean?
- If you try the timestamp less than the first commit time. You will get an exception. Because there is no snapshot before this time.
- If you try the timestamp between the commit time of version zero and the version one, you will get version 0.
- If you want to read the last version, you must provide an exact timestamp for that version as accurate as to the precision of milliseconds.
- If you try the time stamp greater than the first commit time. You will get an exception. Because there is no snapshot after this time.
Great! That is all. I talked almost everything that you get with the open source version of
the delta lake. If you are using data bricks cloud, all of this is also available in
Databricks Spark SQL. You also get Z-Order clustering, fine-grained data skipping, and some
additional perks such as compaction, retention period settings, and other optimizations.
Great! Thank you very much for watching and supporting the learning journal. See you in
the next video.
Keep Learning and Keep growing.